DeepScout: Building a Search-Grounded AI Browser Agent with Fine-Tuned 3B Models
DeepScout: Building a Search-Grounded AI Browser Agent with Fine-Tuned 3B Models
Hackathons often end with a demo, a few screenshots, and a vague one-line summary. I wanted this project to become something more useful: a real case study in AI systems architecture.
At the Mistral AI Worldwide Hackathon I’ve built DeepScout : A search-grounded AI browser agent that takes a user question, generates an optimized search query, searches and scrapes the web, reasons over the retrieved evidence, and returns a structured answer with sources.
What made this project interesting was not just the UI or the model choice. It was the architecture.
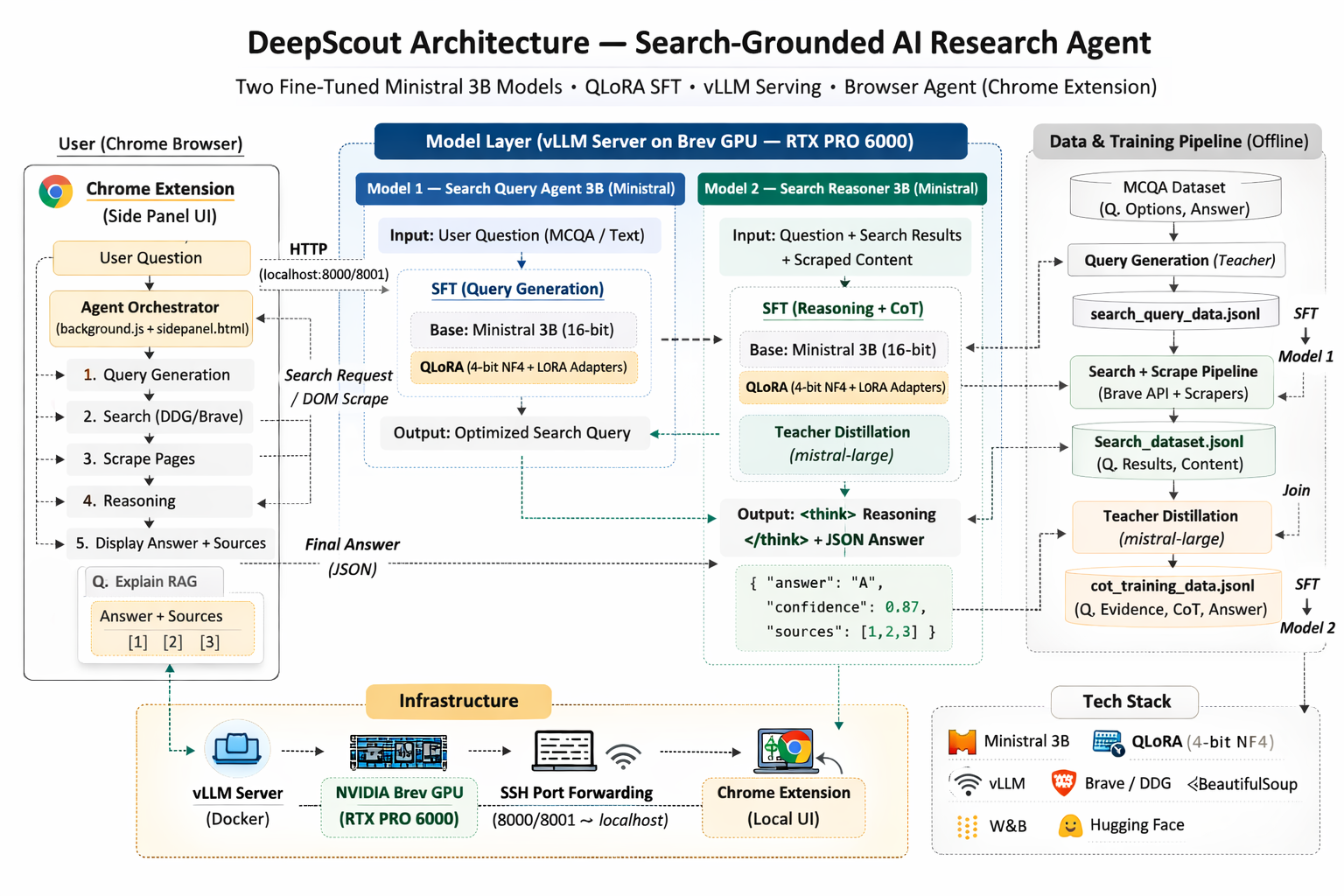
Instead of using one large model for everything, we designed a two-model small-LLM pipeline:
- a query-generation model to improve retrieval quality
- a reasoning model to evaluate web evidence and produce structured answers
We trained two specialized Mistral/Ministral 3B models using Supervised Fine-Tuning (SFT) with QLoRA, loading the base model in 4-bit NF4 quantization during training and updating only LoRA adapters for memory-efficient optimization. We built a teacher-distillation pipeline to generate structured reasoning traces over live search results, served the fine-tuned adapters through vLLM on an NVIDIA Brev GPU instance, and integrated the full workflow into a Chrome extension
This post is a detailed breakdown of what we built, how it works end-to-end, what we shipped, what we planned but didn’t finish, and why this project matters for real-world AI product and solutions architecture.
Why We Built DeepScout
Large frontier models are excellent at reasoning, but using them for every step of a research workflow is expensive and hard to operationalize in interactive products.
At the same time, small models are much easier to deploy, but they often struggle with the exact capabilities required for a useful research assistant:
- generating good search queries
- evaluating source quality
- reasoning over retrieved evidence
- producing structured, reliable outputs
So the core question behind DeepScout was:
How do we make small, deployable models useful for search-grounded reasoning workflows without relying on a large model for every inference step?
What DeepScout Does (High-Level)
DeepScout is a Chrome extension-based research workflow that runs the following pipeline:
- User asks a question
- Query model converts it into an optimized search query
- Browser/search pipeline retrieves and scrapes web results
- Reasoning model evaluates evidence and produces a structured answer
- UI displays answer + sources
In short:
User Query → Query Model → Search + Scrape → Reasoning Model → Structured Answer
System Architecture Overview
1) Query Generation Model (Fine-Tuned Mistral 3B)
The first model is specialized for retrieval optimization.
Its job is to convert noisy user questions (including MCQ-style prompts or extra wording) into short, domain-aware search queries. This step matters because better search inputs produce better evidence, and better evidence improves final reasoning quality.
Why a separate model? Because query generation is a different task from reasoning. Splitting the responsibilities improved modularity and reliability.
2) Browser Search + Evidence Collection Pipeline
Once the query is generated, the extension orchestrates retrieval:
- runs the search query
- collects top results
- scrapes page content from relevant URLs
- formats evidence into a structured context for downstream reasoning
This is what makes the pipeline search-grounded, rather than relying only on model priors.
3) Search Reasoning Model (Fine-Tuned Mistral 3B)
The second model is specialized for evidence-based reasoning.
It takes:
- the original question
- search results
- scraped page content
and returns:
- a structured answer
- confidence / evidence fields (depending on prompt mode)
- source-linked reasoning output
This model was trained using a teacher-distillation pipeline, where a stronger model generated reasoning traces over real search results and scraped content.
The Training and Data Pipeline (What Made This Work)
DeepScout’s key value is not just the final extension — it’s the pipeline that made small-model reasoning possible.
Step 1: Start from a Verifiable Task (NVIDIA Dataset)
We used NVIDIA’s nvidia/Nemotron-RL-knowledge-web_search-mcqa dataset as the source task set. It gave us:
- technical MCQ-style questions
- known answer labels
- a strong base for evaluating search-grounded reasoning workflows
This made the project easier to evaluate than a generic open-ended chatbot demo.
Step 2: Build a Synthetic Query Dataset (for Model 1)
From the MCQ questions, we generated a synthetic dataset of:
- input: question
- output: optimized search query
We used this to supervised fine-tune the first 3B model (query generation).
Step 3: Build the Search + Scrape Evidence Dataset
Next, we took generated search queries and ran a retrieval pipeline using:
- search API calls (Brave)
- result parsing
- page scraping
The output was a structured JSONL dataset containing:
- query
- top search results (title / URL / snippet)
- scraped page content
Step 4: Teacher Distillation for the Reasoning Model
We then used a stronger model to generate reasoning demonstrations over the retrieved web evidence:
... reasoning traces- structured JSON answers
This created supervised training data for the second 3B model.
Step 5: Validation / Filtering
We filtered teacher outputs before training by checking for:
- reasoning trace presence
- parseable JSON
- valid answer fields
This reduced bad labels and improved training quality.
Step 6: Fine-Tune the Search Reasoner with QLoRA
We fine-tuned the reasoning model using QLoRA (LoRA adapters + quantized base model during training) to make 3B training feasible on available GPU resources.
Important distinction: QLoRA in this project was used for training-time memory efficiency, not final deployment-time quantization.
Serving and Deployment
After training, we:
- logged experiments to Weights & Biases
- pushed model artifacts to Hugging Face
- installed and configured vLLM on an NVIDIA Brev GPU instance (RTX PRO 6000)
- served both fine-tuned models for inference
- connected locally via SSH port forwarding
- tested end-to-end inference through the extension pipeline
So while the extension calls a local endpoint like localhost, the actual inference runs on the remote GPU instance.
This gave us a local-first development and demo experience with GPU-backed model serving.
What We Planned but Didn’t Finish (and Why)
From the start, our end goal was not just “a working research agent,” but a research agent that can run cheaply and predictably — ideally on a local workstation, or at least on a small self-hosted GPU. To get there, our original plan included a deployment-time quantization path to shrink memory, reduce latency, and make vLLM serving more efficient.
Here’s what that plan looked like in practice:
1) Train in high quality, then compress for deployment We trained the models using a quality-first setup (teacher distillation + SFT with QLoRA) to get strong behavior into a small 3B model. But for deployment, we wanted to further compress inference by lowering precision in a controlled way.
2) Post-training quantization vs. quantization-aware training (QAT) We explored two directions:
- Post-training quantization (PTQ): take the trained model and quantize it after the fact (fast, but can hurt accuracy or structured output reliability).
- Quantization-aware training (QAT): simulate low-precision during training using NVIDIA ModelOpt so the model learns to stay stable under quantization, then export a deployment-ready checkpoint.
The reason we cared about QAT specifically is that our system depends on structured outputs (ranked sources + answer JSON). Quantization can subtly degrade formatting reliability, even when “accuracy” looks okay. QAT is the more robust route because it trains the model to handle those precision constraints.
3) Intended deployment target The practical target was a quantized checkpoint that could be served efficiently via vLLM (or a compatible runtime), with lower VRAM usage and faster throughput. This is the difference between:
- “Runs on a big GPU instance”
- “Runs on smaller GPUs, cheaper instances, or potentially local hardware”
Why we didn’t finish it in hackathon time We did not complete this path during the hackathon for a simple reason: it’s not enough to “run quantization.” You have to validate it:
- Does the model still produce valid JSON?
- Does it still rank sources consistently?
- Does accuracy hold up on held-out questions?
- Does vLLM load and serve the exported artifact reliably?
Given the limited time, we made a deliberate tradeoff: We prioritized shipping a full working system end-to-end (training → serving → Chrome extension integration → live inference) over integrating an optimization path we couldn’t fully verify before demo time.
Why This Project Matters (Beyond the Hackathon)
DeepScout demonstrates an AI systems pattern I care deeply about:
Use stronger models to bootstrap behavior, then compress and deploy smaller specialized models into real workflows.
This project is not “just fine-tuning.” It’s a full applied AI pipeline that combines:
- Task decomposition into specialized models (query generation + evidence reasoning)
- Teacher distillation (using a stronger model to generate reasoning demonstrations)
- Model adaptation (LoRA / QLoRA fine-tuning on a 3B base)
- Data pipeline engineering (search → scrape → join → validate → JSONL datasets)
- Inference serving (vLLM + OpenAI-compatible endpoints + port-forwarded integration)
- Tool + browser orchestration (the extension actually drives search and page scraping)
- Product integration (a usable Chrome extension interface, not a notebook demo)
That combination is what makes AI real in production: the system, not the model in isolation.
What I’d Improve Next
In building DeepScout, the next upgrades are clear and practical:
- Stronger evaluation on held-out benchmarksBase vs fine-tuned comparisons, plus end-to-end success metrics: accuracy, JSON-valid rate, citation quality, and latency.
- Higher structured-output reliabilityTighter schema enforcement, better JSON sanitization, and “fail-soft” fallback strategies when parsing breaks.
- Finish the quantization deployment pathComplete and validate the QAT/ModelOpt pipeline end-to-end:
- calibrate on representative prompts
- export a quantized checkpoint
- serve it reliably
- measure real gains: VRAM, throughput, latency, and output stability
- Better source ranking + groundingMore robust ranking heuristics, stronger citation alignment, and clearer evidence-to-claim mapping.
- Production hardening the extension pipelineCaching, retries, better error handling, and less intrusive browsing behavior for a smoother UX.
DeepScout started as a hackathon build, but it turned into something much more valuable: a concrete example of how to architect and ship an end-to-end AI system under real constraints.
The key lesson for me was simple:
Small models become genuinely useful when you combine task decomposition, grounded retrieval, distillation, and real deployment infrastructure.
If you’re working on applied AI systems, inference infrastructure, or search-grounded workflows, I’d love to connect.